Share





Download the
Global Threat
Intelligence Report
本記事は2023年6月にNTTセキュリティ・ジャパンが発表した論文『Detecting Phishing Sites Using ChatGPT [1]』の内容を解説したものです。
はじめに
こんにちは、グローバル技術開発部の小出です。
ChatGPTを悪用したサイバー攻撃の可能性が議論されています。例えば、解析回避機能を実装したフィッシングサイトやマルウェアのソースコードを自動で作成できることが指摘されています [2,3]。AIを利用して自動化されたサイバー攻撃に対抗するために、どのような防御方法が有効でしょうか?サイバーセキュリティにおけるChatGPTの活用、特に悪意のあるWebサイトの分析はこれまでほとんど議論されていませんでした。そこで本記事では、ChatGPTを用いたフィッシングサイトの検出について実験しました。実験の結果、ChatGPT(GPT-4)によって、フィッシングサイトを98%以上の精度で識別できることが明らかになりました。
アイディア
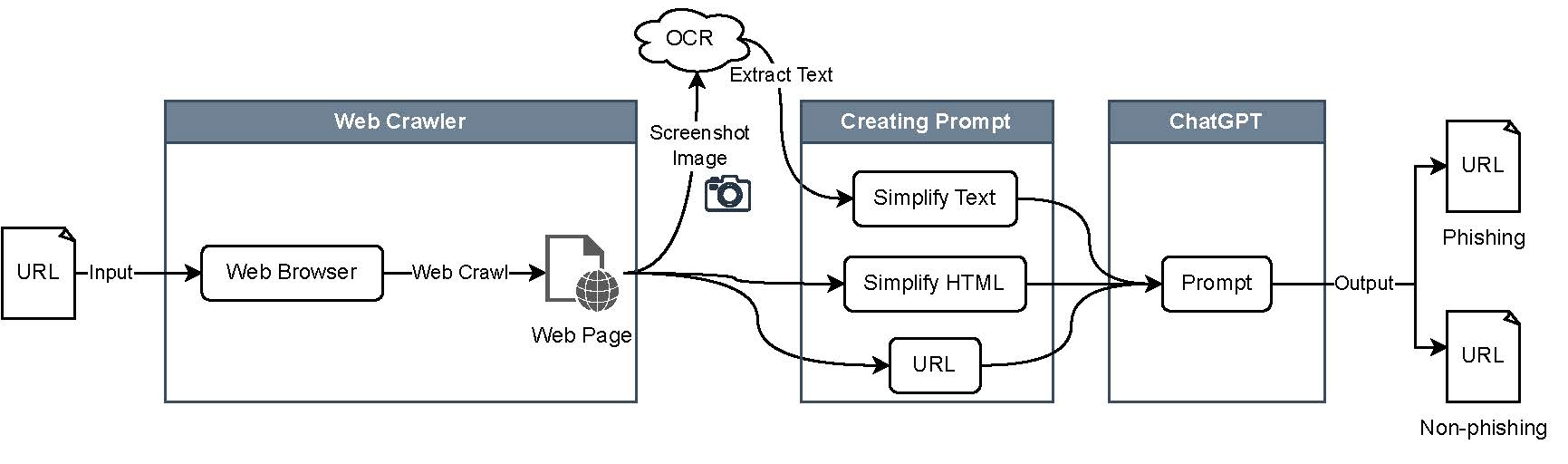
本実験の目標は、ChatGPTにWebサイトがフィッシングサイトか否かを判定させることです。フィッシングサイトは正規のWebサービスになりすまし、ソーシャルエンジニアリングのテクニックを用いて被害者を騙します。例えば、有名なWebサービスのロゴやブランド名を悪用したり、偽のウイルス感染警告や現金当選画面を表示することがあります。フィッシングサイトを判定するための手がかりとして、URLとHTMLが重要な要素となります。正規のWebサイトをコピーして作成されたフィッシングサイトを検出するためには、URLが正規のものでないと正しく判定できる必要があります。フィッシングサイトのHTMLに含まれるテキストは、ユーザに対する心理的な働きかけが含まれることがあります。また、HTMLにはテキストだけでなく、ログインフォームやクレジットカード番号の入力欄などの構造的な要素も含まれています。
このような自然言語やプログラミング言語の高度な分析では、まさにChatGPTが活躍しそうです。嘘の情報や被害者に対して要求する行動を、Webサイト内の文章とHTMLの双方から特定できることが期待されます。また、画像ファイルに表示される文字はHTMLから読み取ることはできません。本実験では、Azure Cognitive ServicesのOCR(光学文字認識)を使用してスクリーンショット画像をテキストデータに変換しました。ChatGPTにはトークン数の制限があるため、本実験ではGPT-3.5の4096トークンに収まるように、HTMLとOCRで抽出したテキストの簡易化を行いました。
プロンプト作成
精度が求められるタスクでは、ChatGPTに与えるプロンプトを改善するためにプロンプトエンジニアリング (https://www.promptingguide.ai/ )が必要です。事前の分析として、HTMLとURLを与えて、フィッシングサイトかを判定してください、という単純なプロンプトを試しました。しかしその結果、フィッシングサイトではないWebサイトが無理やりなこじつけによりフィッシングサイトと判定されることが多数ありました。例えば、ログインページでユーザ名とパスワードを要求しているからフィッシングサイトと判定される、といった回答が得られました。
そのため、プロンプトの設計にあたり、フィッシングサイトの判定を以下の4つのサブタスクに分割し、段階的にChatGPTに回答させるようにしました。
1. ソーシャルエンジニアリングの分析
- 検査対象のWebサイトに正規のWebサイトでは見られない心理的な誘導のテキストが含まれているか分析します。具体的な例として、偽の当選(スマホやギフトカード)や偽のウイルス感染警告の表示などを与えます。
2. ブランド名の抽出
- 検査対象のWebサイトが何らかのサービスや企業を騙っているかを分析します。WebサイトのURLと抽出したブランドに関連する正規のドメイン名を比較し、不一致があるかを確認します。
3. 判定の根拠の説明
- ChatGPTにフィッシングサイトを判定するまでの考える時間を与えます。判定の根拠を説明することで回答の精度の向上を期待し、レスポンスを分析しやすくします。
4. 判定結果の出力
- レスポンスを機械的に処理するために、JSON形式のテキストで回答します。回答には、総合スコア、ブランド名、フィッシングサイトか否か、ドメイン名の怪しさ、という4つの項目が含まれます。
以下が実際に使用したプロンプトのテンプレートです。検査対象のWebサイトから、URL、HTML、OCRで抽出したテキストをプロンプトに入力します。
プロンプトテンプレート:
| You are a web programmer and security expert tasked with examining a web page to determine if it is a phishing site or a legitimate site. To complete this task, follow these sub-tasks: 1. Analyze the HTML, URL, and OCR-extracted text for any social engineering techniques often used in phishing attacks. Point out any suspicious elements found in the HTML, URL, or text. 2. Identify the brand name. If the HTML appears to resemble a legitimate web page, verify if the URL matches the legitimate domain name associated with the brand, if known. 3. State your conclusion on whether the site is a phishing site or a legitimate one, and explain your reasoning. If there is insufficient evidence to make a determination, answer "unknown". 4. Submit your findings as JSON-formatted output with the following keys: - phishing_score: int (indicates phishing risk on a scale of 0 to 10) - brands: str (identified brand name or None if not applicable) - phishing: boolean (whether the site is a phishing site or a legitimate site) - suspicious_domain: boolean (whether the domain name is suspected to be not legitimate) Limitations: - The HTML may be shortened and simplified. - The OCR-extracted text may not always be accurate. Examples of social engineering techniques: - Alerting the user to a problem with their account - Offering unexpected rewards - Informing the user of a missing package or additional payment required - Displaying fake security warnings. URL: {URL} HTML: ``` {HTML} ``` Text extracted using OCR: ``` {OCRで抽出したテキスト} ``` |
実験
それでは実際に、ChatGPTによるフィッシングサイト検出を試してみましょう。上記のプロンプトを使用してフィッシングサイトを判定する実験を行いました。実験には、フィッシングサイトと非フィッシングサイトの2種類のデータを用意しました。フィッシングサイトのURLは、OpenPhish (https://openphish.com/ )とPhishTank (https://phishtank.org/ )という2つのフィッシングインテリジェンスから収集しました。さらに、Twitterに投稿されたフィッシング被害報告からもURLを収集しました [4]。独自のWebクローラを使用して、計147のブランドに偽装したフィッシングサイトを収集しました。これらのフィッシングサイトは22の異なる言語に分布していました。一方、非フィッシングサイトとしては、フィッシングサイトが偽装したブランドの正規のWebサイトや、人気サイトリストTranco(https://tranco-list.eu/)からデータを収集しました。非フィッシングサイトは34の言語に分布していました。
- フィッシングサイト: 1,000件
- 非フィッシングサイト: 1,000件
Azure OpenAI Serviceを使用し、GPT-4とGPT-3.5の2つのAPIに同一のリクエストを送信しました。レスポンスに含まれるJSONテキストを解析し、"phishing"キーまたは"suspicious_domain"キーのいずれかまたは両方の値がtrueである場合、ChatGPTの判定をフィッシング、どちらもfalseの場合は非フィッシングとして集計しました。
実験の結果、フィッシングサイトの検出精度に関して、以下の結果が得られました。True Positive Rate(フィッシングと予測されたデータのうち、実際にフィッシングであるデータの割合)は、GPT-3.5が86.7%、GPT-4が98.4%でした。False Positive Rate(非フィッシングと予測されたデータのうち、実際にフィッシングでないデータの割合)は、GPT-3.5が1.5%、GPT-4が1.7%でした。まさに驚くべき精度でフィッシングサイトを検出できました。ChatGPTは、様々な言語によるソーシャルエンジニアリングを正確に特定できていたため、ほとんどの専門家はフィッシングサイトの判定においてすでに太刀打ちできないかもしれません。
以下の表はそれぞれの実験結果を示しています。GPT-3.5とGPT-4は、非フィッシングサイトを識別する能力は同等でした。しかし、GPT-3.5ではフィッシングサイトを誤って非フィッシングサイトと判定するケースが多くありました(False Negativeが133件)。一方、GPT-4ではこの誤判定が大幅に改善されており、わずか16件のFalse Negativeとなりました。
GPT-3.5:
| フィッシング予測 | 非フィッシング予測 | |
| フィッシング結果 | 867 | 133 |
| 非フィッシング結果 | 15 | 985 |
GPT-4:
| フィッシング予測 | 非フィッシング予測 | |
| フィッシング結果 | 984 | 16 |
| 非フィッシング結果 | 17 | 983 |
フィッシングサイト検出結果の例
ChatGPTが正しくフィッシングサイトを検出できていた応答結果の例を紹介します。
フィッシングサイト 例1:

レスポンス:
| 1. The URL has a suspicious domain name with random characters: http://www.a-7rgupy-7dbxd[.]com/top/campaign.php Additionally, the text extracted using OCR includes elements referring to a prize (9億円当選, which means "winning 900 million yen"), which is a common social engineering technique used in phishing attacks. 2. The brand name found in the HTML and OCR-extracted text is "docomo," which is a Japanese telecommunications company. The legitimate domain for this brand is "https://www.nttdocomo.co[.]jp/", not the given URL. 3. The site is likely a phishing site, as the URL has a suspicious domain and the content includes typical social engineering techniques. 4. JSON-formatted output: ```json { "phishing_score": 8, "brands": "docomo", "phishing": true, "suspicious_domain": true } ``` |
このフィッシングサイトは、NTTドコモを装い、ユーザーの関心を引くために偽の現金当選を表示しています。ChatGPTは、「9億円当選」という非現実的な煽り文句がソーシャルエンジニアリングのテクニックであると正しく認識しています。また、「docomo」というブランド名を抽出し、このフィッシングサイトのドメイン名と一致していないことを指摘しています。その結果、「phishing」と「suspicious_domain」の両方がtrueと判定され、正しくフィッシングサイトと判定されました。
フィッシングサイト 例2:
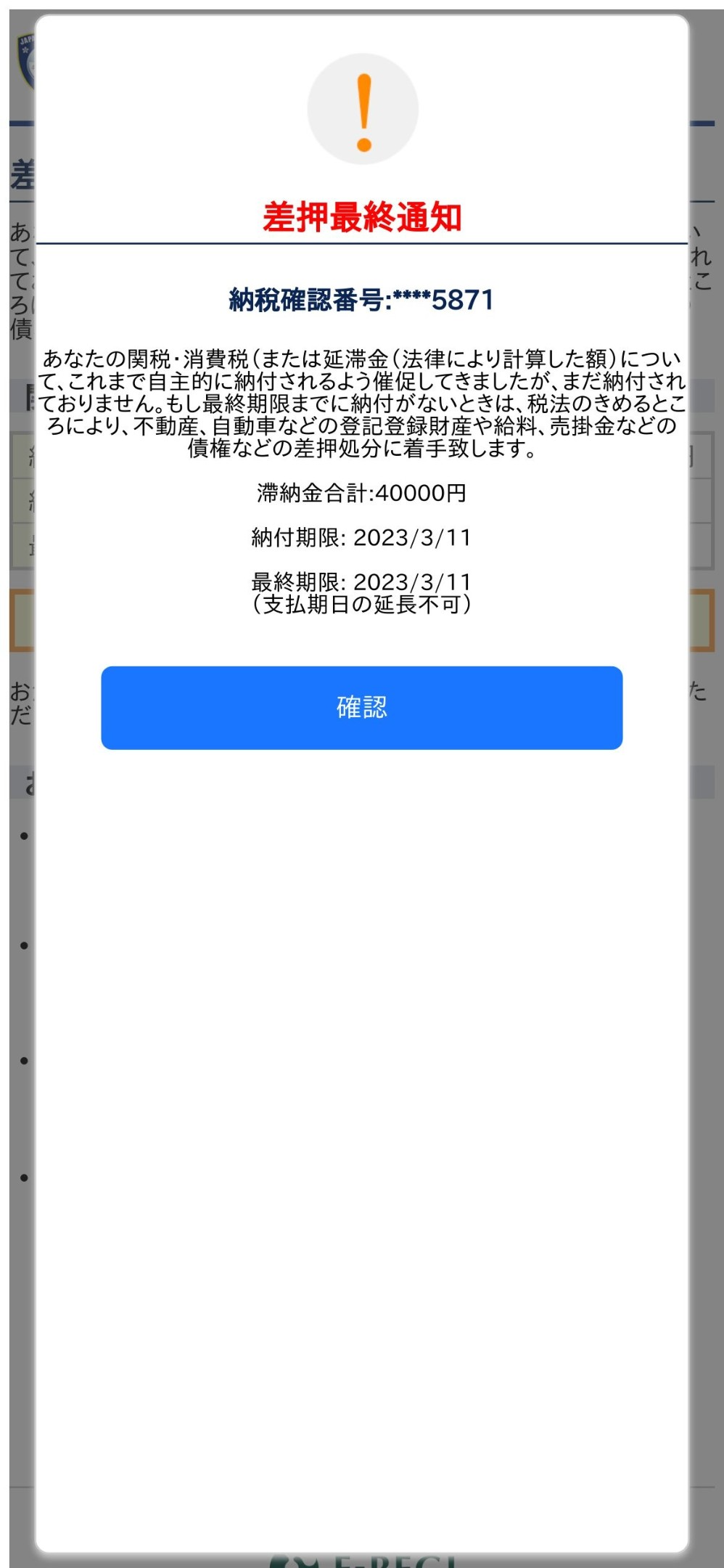
レスポンス:
| 1. Analyzing the HTML, URL, and OCR-extracted text, I found the following suspicious elements: - The URL is suspicious because it uses a non-legitimate domain (`duckdns.org`). - The HTML contains alerting text that seems like a phishing attempt, such as "差押最終通知" (Final Attachment Notice), informing the user about an unpaid tax and urging them to pay using specific methods. 2. The brand name found in the HTML is F-REGI. The legitimate domain for F-REGI is `f-regi.com`. However, the URL in this case does not match F-REGI's legitimate domain. 3. Based on the analysis, I conclude that this site is a phishing site. 4. JSON-formatted output: ``` { "phishing_score": 8, "brands": "F-REGI", "phishing": true, "suspicious_domain": true } ``` |
続いて、最近多発している税金の納付を要求するフィッシングサイトの検出結果を説明します。この例では、税関のロゴを表示し、決済代行サービスF-REGIを装い、税金の滞納の警告と支払い要求を行っています。ChatGPTは、「差押最終通知」などの警告や支払いを促すテキストがフィッシングに関連していると正しく分析しています。このフィッシングサイトのHTMLには「Copyright © 2002-2023 F-REGI Co.,Ltd. All Rights Reserved.」というコピーライト表示が含まれており、ブランド名「F-REGI」を抽出していますが、ドメイン名が正規のF-REGIと異なることを指摘しています。さらに、ダイナミックDNSサービスDuckDNSを使用していることから正規のものではないと指摘し、最終的にフィッシングサイトと判定しました。
フィッシングサイト 例3:
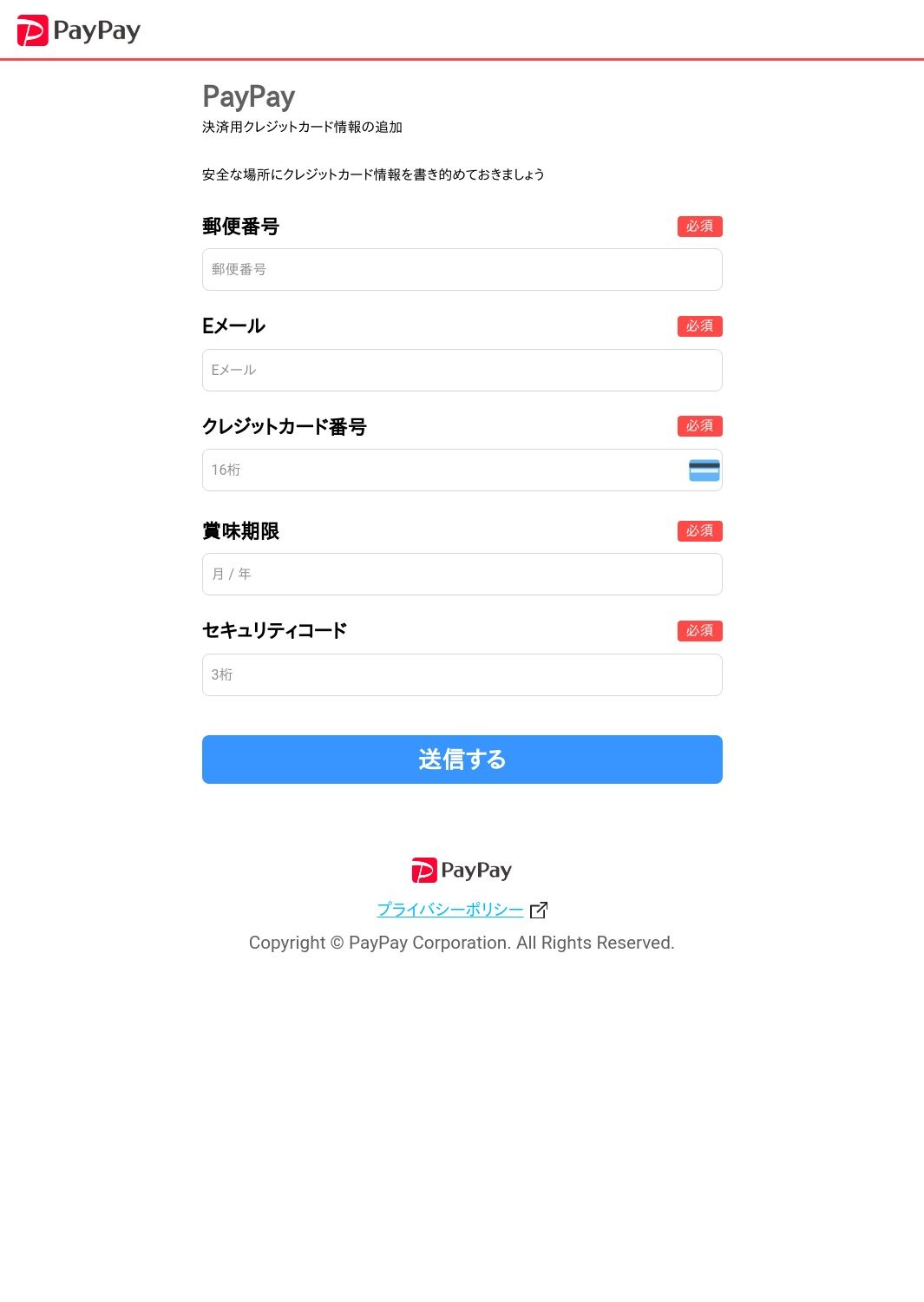
レスポンス:
| 1. Analyzing the HTML, URL, and OCR-extracted text, we can identify the following suspicious elements: - The URL is not the official PayPay domain (https://jp-pay-pay.web[.]app/). The legitimate domain for PayPay Corporation is https://www.paypay.ne[.]jp. - The HTML layout resembles an official PayPay site, but it's asking for sensitive data such as credit card information, email, and postal code. 2. The identified brand name is PayPay. 3. Based on the analysis, the site is a phishing site because: - The URL does not match the legitimate domain associated with the PayPay brand. - The site asks for sensitive data and resembles the official PayPay site to deceive users. 4. JSON-formatted output: ```json { "phishing_score": 10, "brands": "PayPay", "phishing": true, "suspicious_domain": true } ``` |
このフィッシングサイトは、PayPayを装ってクレジットカード情報や個人情報を要求しています。PayPayの正規のWebサイトのレイアウトに似せていますが、心理的な誘導を行う警告や興味を引くテキストは見当たりません。このようなソーシャルエンジニアリングのテクニックがテキストに含まれないフィッシングサイトであっても、ChatGPTはブランド名を特定し、そのURLが正規のものでないことを理由に正しくフィッシングサイトと判定することができました。
まとめ
ChatGPTを用いたフィッシングサイト検出の実験結果を紹介しました。この実験により、GPT-4を活用することで、フィッシングサイトを98%以上の高い精度で検出できることが明らかになりました。特に、ドメイン名が正規のものかを判定する能力と、フィッシングサイトに含まれるソーシャルエンジニアリングのテクニックを識別する能力に優れていることがわかりました。ChatGPTは、フィッシングサイトに悪用されるような著名なWebサービスであれば、検査対象が正規のドメイン名であるか正しく識別できました。また、Webサイトに表示されるテキストが心理的な影響を与えるか、といった文脈を踏まえた高度な分析もできています。今後も、ChatGPTの潜在能力をさらに詳しく調査し、様々なサイバー攻撃の分析に活用していきたいと考えています。
参考文献:
[1] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba. 2023. Detecting Phishing Sites Using ChatGPT. https://arxiv.org/abs/2306.05816
[2] OPWNAI : Cybercriminals Starting to Use ChatGPT - Check Point Research https://research.checkpoint.com/2023/opwnai-cybercriminals-starting-to-use-chatgpt/
[3] Sayak Saha Roy, Krishna Vamsi Naragam, and Shirin Nilizadeh. 2023. Generating Phishing Attacks using ChatGPT. https://arxiv.org/abs/2305.05133
[4] Hiroki Nakano, Daiki Chiba, Takashi Koide, Naoki Fukushi, Takeshi Yagi, Takeo Hariu, Katsunari Yoshioka, and Tsutomu Matsumoto. 2023. Canary in Twitter Mine: Collecting Phishing Reports from Experts and Non-experts. https://arxiv.org/abs/2303.15847